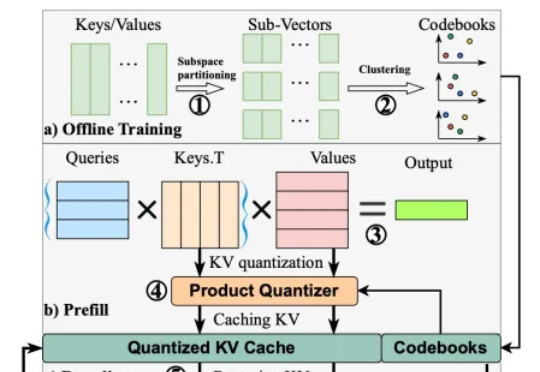
原来Veo 3早有苗头!人大联合值得买科技在CVPR 2025提出全新「图像到有声视频」生成框架
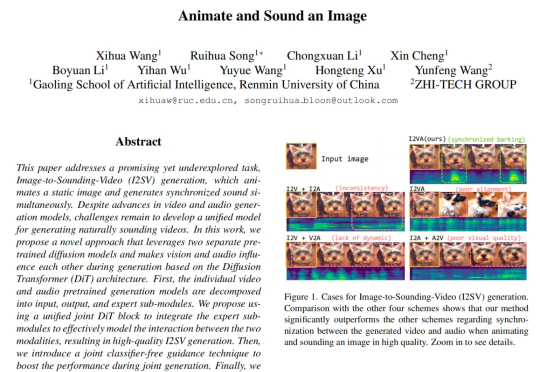
原来Veo 3早有苗头!人大联合值得买科技在CVPR 2025提出全新「图像到有声视频」生成框架来自中国人民大学高瓴人工智能学院与值得买科技 AI 团队在 CVPR 2025 会议上发表了一项新工作,首次提出了一种从静态图像直接生成同步音视频内容的生成框架。其核心设计 JointDiT(Joint Diffusion Transformer)框架实现了图像 → 动态视频 + 声音的高质量联合生成。
来自主题: AI技术研报
10463 点击 2025-05-29 14:20